Lecture 01 lecture:Modern Analytical Database Systems
这个学期讨论的是OLAP以及现代系统,并且探讨如何在现代系统中构建这些独立组件,但是还是属于一个高层概览
today's agenda
- background of the Modern OLAP Databases
- Architecture Overview
- Query Execution
- Project Discussion
Background
OLTP中真正面向外部世界的是其接口,无论是面向人还是计算机,比如网页界面或REST接口,他们负责接收新信息,获取新的状态,接收新的变化,并希望尽快将这些信息存储起来。
其实,我感觉OLTP就是我们平时接触到的做增删改查
但是对于大型企业来说,一旦接收了做够多的信息,就希望能够提出新的信息,比如做预测,做决策,这就涉及到了OLAP.
在最早,人们将这种分析性工作运行在“单体数据库系统”中,比如MySQL, SQLite, DuckDB, Postgres……
对于这一领域(就是提取新的数据做分析), 可以说是最早的研究,那时候主流的仍然是经典的数据库系统架构,也就是我们CMU15445所讨论的那种结构,row store, pages in disk, buffer pool ……
但是如果做OLAP查询,其实性能并不好,在CMU15445中也提到了,其实是只读取了数据集的一部分,但要整行存储, 但是后来有了列存储
但当时人么意识到速度较慢,就开始构建data cubes(数据立方体)
Data Cubes
可以将这些视作类似物化视图或预计算的查询聚合,比如基于不同维度的根组,并会生成一个或多或少的数据立方体数组,并存储在数据库中。对于任何分析查询,都会尝试定位到这个数据立方体。

Data Warehouses
2000s开始,人们开始研究专门的数据库,叫做数据仓库,专门为分析性工作负载而设计
这就是我们在论文中看到的data warehouse,我感觉说白了这还是个数据库,只不过专门用于分析工作负载
但是其中很多数据库的分支都是从Postgres开始的

但是Postgres是个行存储,但这些系统都彻底剥离了很多存储内部结构,构建了针对列存储的组件
在图中除了Data Allegro和Monet之外,其余都是Postgres的分支
这些数据库还是单体数据库,而且有自己的格式,其实这也是一个缺点,在论文中提到了。
这些数据库架构都是“无共享”结构,但他们假设了数据库集群中的每个计算节点都拥有磁盘,内存和CPU资源。每个节点负责对整个数据库的某一部分进行排序
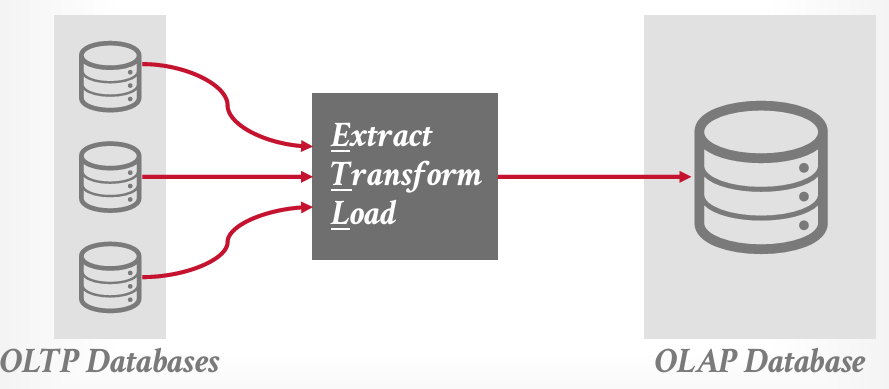
其实看过论文这张图很好理解,左边的OLTP是所有的操作型数据库,比如说企业的进销存系统可能是一个数据库,什么别的系统可能是一个数据库,将这些信息全部整合到单一的数据库,便于分析数据,这也是论文中提到的第一代系统
其中整合的过程就是ETL工具“提取,转换和加载”,在这其中需要对数据捕获,比如定期从这三个数据库中获取更新,对他们进行一定程度的修改以清理数据,比如实体解析,Pavlo和Andy P是一个人。
但同样,右边由于也是一个数据库,所以对于data warehouse来说,希望它对所有内容拥有完全控制权,所以必须提前设置好schema
这是个无共享系统,若要扩展系统的容量,就必须增加更多的节点
Shared-Disk Engine
2010s,Shared-Disk Engine开始发展,共享磁盘引擎时代
这里的理念是我们不再让数据库系统自己来管理存储层,而是卸载overload给其他软件或服务来处理,而这个其他的软件和服务,在云服务中,可能是对象存储,比如S3。由于我们不再需要负责管理数据的存储,所以我们开始尽可能的优化计算层
其实我感觉这里稍微一点点问题,但没那么重要,我感觉Andy老师是想说对于data warehouse来说还仍然采用专有数据格式,也就是无法移植。
但其实对于对象存储来说,已经可以把视频,图片扔进去了。
这种架构的核心在于实现了计算与存储的分离
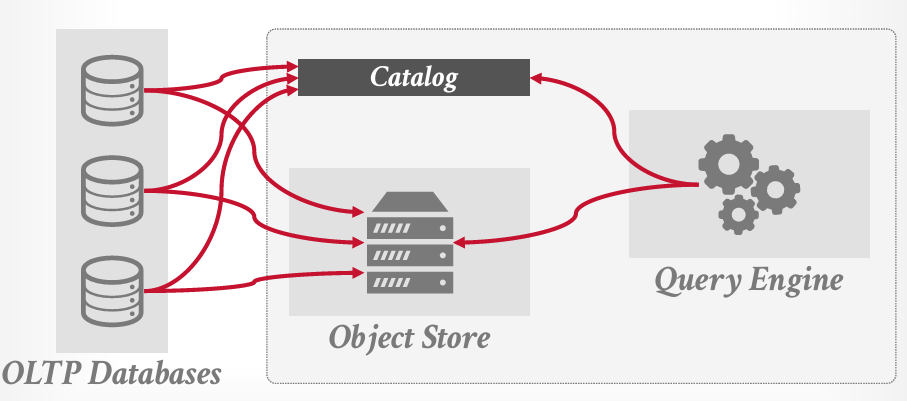
OLTP中的数据经过ETL放入Object Store, 这里有一个核心的组件是Catalog,会告知Catalog,这是我刚存放的文件,内容,在哪里等等。
这时候如果要执行查询,侧边的查询引擎去Catalog中看数据来自哪里 然后从Object Strore中拿取数据。
其实看了论文之后,其实我觉得这里除了Query Engine之外,还有别的引擎比如ML的引擎,可以访问Object Store中的数据直接进行学习,但是Query Engine在第二代架构中最后还是放入了data warehouse中.
上面图中右边框中的内容,是我们这学期要讨论的内容,这是一个简化的经典的核心架构。
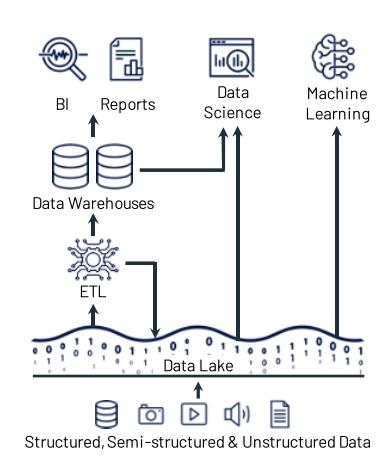
LakeHouse Systems
前面的系统有很多问题,在论文中提到的简单来说就是下面几点
- 数据陈旧,从OLTP要ETL进Data Lake. 当然如果要进行决策等用到SQL语句的话还要在ETL进Data Warehouse.
- 可靠性,简单来说Data lake中没有数据的格式,在ETL到Data warehouse中可能会出现问题 当然这也设计到一个问题,非结构化的数据怎么ELT? 所以最后摒弃了整个Data warehouse,我觉得这也是原因之一
- ML虽然可以直接用Data Lake中的数据,但是一般的语言比如Pytorch,Paddle都是用的Python,没法利用到SQL的数据优化
所以有了LakeHouse架构,这也是我们看的这篇论文所介绍的核心内容,21年的一篇论文
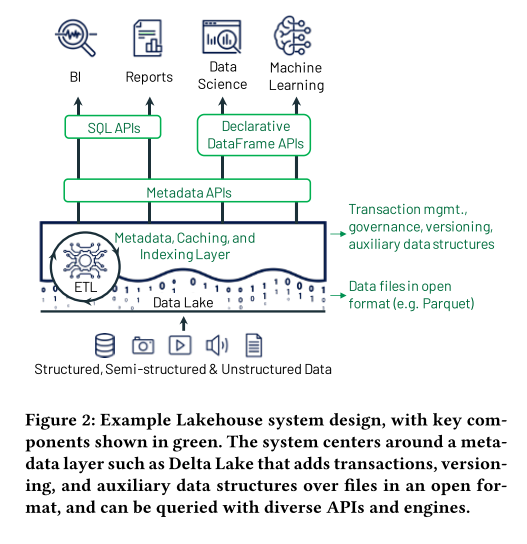
事实上核心我觉得就是摒弃了data warehouse,但是设计了Caching, Index, Metadata等机制在Data Lake中模拟了数据库的事务管理等,同时由于Machine Learning等直接访问Data Lake,所以设计了声明式的API,可以像SQL那样编程,正好利用了类似SQL优化的机制。
但这里说明一点,在本学期中其实并没有去讨论完全非结构化的数据(比如视频,图片),更多的是关注的半结构化的数据, 比如Json。
但是对于非结构化的数据,Andy老师也提到了一个点,就是利用一个Transformer模型或某种机器学习框架,从中提取图像或视频的关键内容的信息,经过这种转换输出的都将具有结构化特征
OLAP DBMS Components
先在的趋势就是,我们逐渐摆脱了单一的数据库系统,现在人们正在构建服务或独立组件,这些服务和组件与整个系统分离。
这其实也是本学期的一个项目,就是构建任意一个主题的组件。
理论上,不同的服务或者是组件能够公开并保持一个稳定的API,其他服务就能够理解使用这个API,然后就可以开始交换这些组件而不用从零开始构建整个系统。
The Composable Data Management System Manifesto | Proceedings of the VLDB Endowment或者去CMU15721的官网也有这篇论文,这是来自Facebook团队的人,基本上他们的观点是,组件,服务正式人们构建数据库系统的方式,拥有独立的组件,相互操作
Architecture Overview
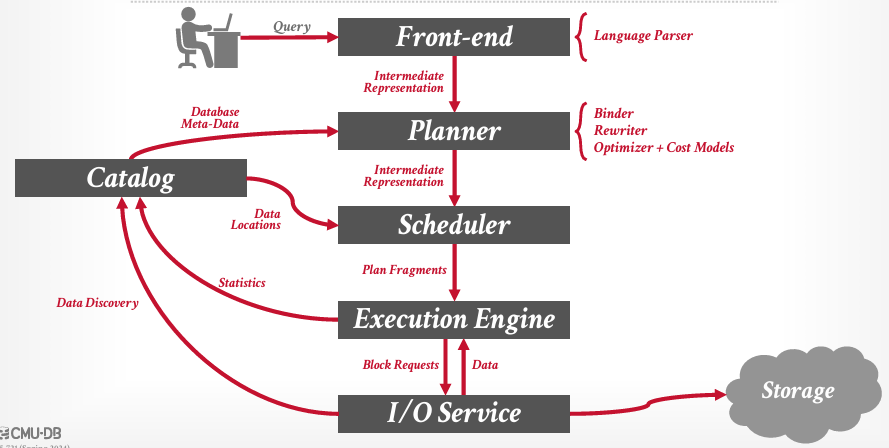
在最顶层,有一些用户,他们发出一个查询,假设是SQL,到系统的前端部分,这将包含一个语言解析器,即SQL解析器,会将SQL查询转换为一组指定结构的token.
接着把SQL查询的中间表示形式发送给某个规划器,他们拥有负责解析的binder绑定器, 期中存在一个指向表名的token, 对查询进行Rewriter重写,转换为更优的规范形式, 然后拥有一个优化器Optimizer, 能够从数据本身衍生出的陈本模型进行基于成本的搜索,以确定最优的执行方案。同时Planner这一部分需要跟Catalog交互,比如说我有一个token,这真的是一张表嘛?有那些列?实际存储在哪儿等等
经过Planner后得到了一个系统中实际执行的物理计划,Scheduler将会审视这一点,并表示,好的,你想对这些数据运行这个计划,前往目录查明数据实际上物理存储的位置,或者在我的集群中,谁负责实际执行该数据。
随后分派给Execution Engine执行引擎,暂不考虑如何分发查询,以及谁负责确保计算节点始终运行等事宜,这些我们暂时忽略
最后,在退出查询计划和操作符的时候,需要IO请求从存储中获取数据。将向其发起请求服务,然后该IOS服务器负责访问存储设备Storage.
随后,系统获取这些数据快,并将其返回给执行引擎,以便执行引擎能够计算其所需计算的任何内容 计算答案后将会一路向上回到栈顶送达用户
同时还有两件事会发生。可以将数据更新到Catalog中
Architecture & Query Execution
Distribute Query Execution
本学期将从高层上探索所描述系统的框架,都是分布式的,Snowflake, Redshift也是分布式的,我们所展示的这些系统,都是横向扩展的分布式数据库系统。
但我们即将要读的大多数论文,实际上都是关于单节点执行的
在较高层次上,分布式查询与单个节点上的操作本质是一致的。分布式系统会额外做一些工作,比如将数据从一个节点转移到另一个节点,这其实与从这个CPU核心发送数据到另一个CPU核心是没有区别的
查询计划在理想情况下是一个DVG(有向无环图) -- 在CMU15445提到过
数据系统将审视查询计划,确定所需访问的数据,了解数据进入操作符的位置,以及下一步需要流向何处,提前知道这一切,系统才能在运行查询的时候确切知道如何协调和安排事务,以及将数据发送到何处
我们将要探讨的是如何在这一过程中融入一些自适应性,即我们如何实时调整查询计划,以及如何根据数据表现移动数据或上下伸缩资源。
这是关于执行引擎与IOS服务器协同工作的高层次概述
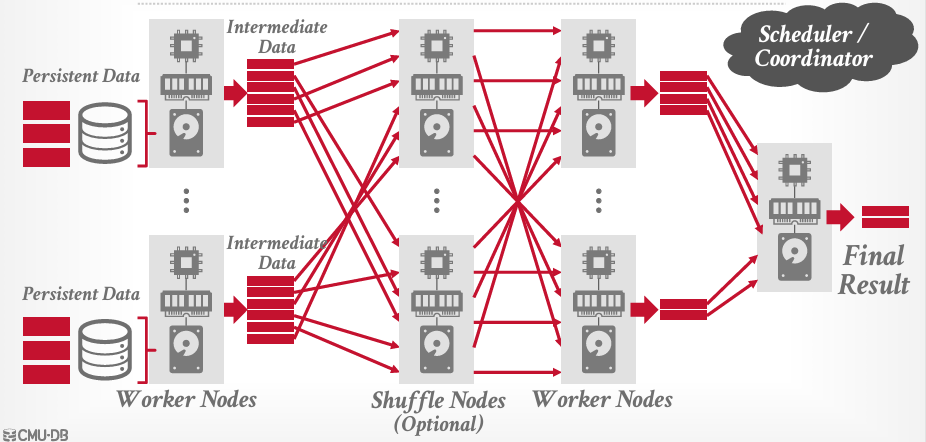
我们有工作节点,有本地CPU,本地内存,本地磁盘,然后在查询开始时进行检索,查询计划的叶节点,如顺序扫描等访问我们称之为持久数据的内容(这些就是我们数据库表中的底层元组). 这些数据是源自于IOS服务,还是本地磁盘还是对象存储,都没有差别
所有的节点将为我们的查询计划执行一些计算,并生成中间结果(Intermediate Data),这些迭代结构式操作符生成的产物,需要传递给查询计划的下一阶段
我们分布数据的方式之一是通过shuffle nodes(洗牌节点)进行,这里的思想是对正在扫描的数据,以及在结果中生成的数据,基于某个分区键进行哈希处理,然后将结构分发到shuffle Nodes。
然后Shuffle节点负责将数据分发到查询计划的下一阶段,即worker nodes,这其中没有任何计算,基本就是进出操作,将数据作为键值对存储在内存中发送给工作节点。
这是可选的,并非所有的OLAP数据系统都这么做, BigQuery是著名的执行此操作的系统
这些工作节点产生更多的中间结果,然后将这些结果发送到某个最终节点进行最终的合并或聚合,已生成我们发送会用户的最终结果。
居于这一切之上的,跟踪当前情况的 是 Scheduler
在系统架构中,需要考虑的一个因素是: 如何在不同节点的操作符之间传输数据,也就是说,如果查询需要的数据不在本地节点,需要怎么让查询和数据传输到一个节点上的问题,有两种方法
- Push Query to Data(将查询push到数据所在为止)
- Pull Data to Query(将数据pull到发起查询的节点)
不过随着系统越来越现代化,这两种方法的界限越来越模糊
Approach 1: Push Query to Data
推送方法的理念是,查询本身,无论是SQL字符串还是查询计划的中间表示,都将远小于数据本身。那么就将query push到data的地方去,在那里进行处理,将中间结果发送回来。理想情况下,中间结果会比持久数据更小
再过去磁盘和网络速度及其缓慢时,这种做法是非常合理的。但在这种方法中面临的问题是,可能没有在数据实际存储位置的计算能力,如果我们使用的是S3,api就仅包含获取,放置,和删除操作
所以这个时候就需要将数据拉取到查询所在的位置
Approach 2: Pull Data to Query
将数据拉取到查询的节点,处理之后生产中间结果传给下一个阶段。
但是关键在于,查询相对于所处理数据的大小将远远更小
所以在过去没有共享磁盘模式下,一般都采用的是Approach 1, 在共享磁盘模式下,若忽略对象存储带来的额外特性,将会采取Approach 2.
但是对象存储可能会有额外特性,比如S3这样的服务中,有一个选择操作符,使得在发起GET请求时,可以发起一个看似SQL查询的指令到S3

当然并不是说所有的都适合这样谓词下移的操作,假如有一个文件多个查询都要用到而且是不同的选择谓词,这个时候将所有文件拿到然后分别处理 可能成本会更低
Shared-Disk
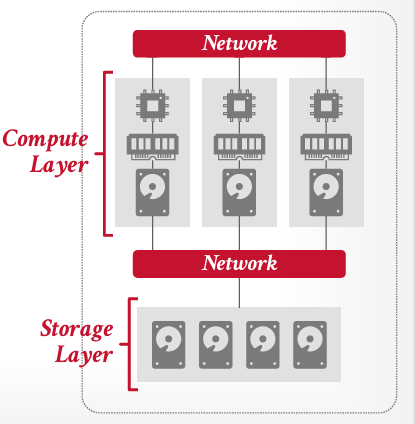
Shared-Disk相对于Shared-Nothing的好处是,数据是存在最下层的,可能是S3这种对象存储(不需要考虑数据备份等,Amazon都帮助做好了)所以增加或者减少一个节点不需要重新分发数据
Object Stores
- 数据库的持久化数据切分成块 存放到对象存储中
- PAX 列式布局:提高局部性和压缩效率
- 每个文件的头部或者尾部包含该文件的元数据,包括列的偏移位置,压缩算法,索引信息,zone maps(每列的最大值最小值等信息)等
- 通过访问header可以判断是否可以跳过
- 每个云厂商都有自己的访问接口API: put, get, delete.
下一节课会详解列式存储的东西
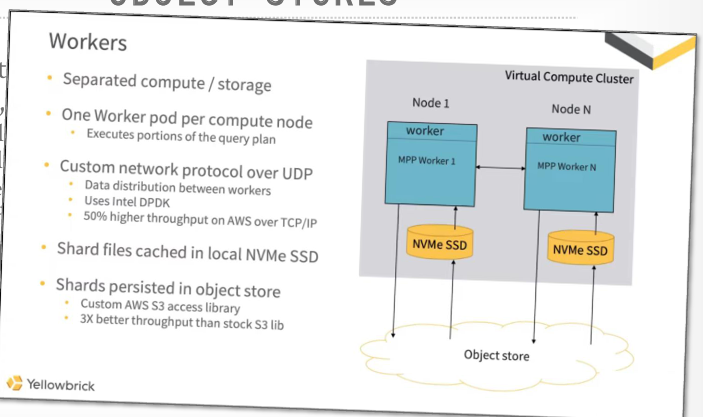
这是我们未来要讨论的一个数据库叫Yellowbrick,yellowbrick最初是一个share-nothing的本地数据库系统,他们有自己的定制硬件,对其组装并进行了优化,后来yelllowbrick转换为基于云的数据库系统,但他们发现将系统迁移到公有云上运行时,对象存储的性能低于他们以往在本地版本的设备中的体验,最终他们提供了亚马逊或操作系统提供给他们的功能,进行了定制化处理,例如他们弃用了亚马逊的库,自行编写了库来使用英特尔DBDK来调用S3服务。他进行的是内核旁路操作,将在本学期后面学到,主要是实现了对S3的快速查找,获取内容或所需数据,并且不在内核中进行复制,而是立即将其直接传递到用户空间
这也说明了有办法提高对象存储的速度
Last Class
下节课的论文是Andy老师写的 探讨了Parquet和ORC的内部结构 后面还探讨了一些关于GPU的内容,但是本课程只讨论在CPU上的运行
另外下节课会介绍一种新变种,新实现的文件格式,据称他们在性能上优于Parquet和ORC.